INTRODUCTION
This article defines crawl budget, outlines why Google cares about it, lists the factors that influence it, and concludes with how it can be optimized.
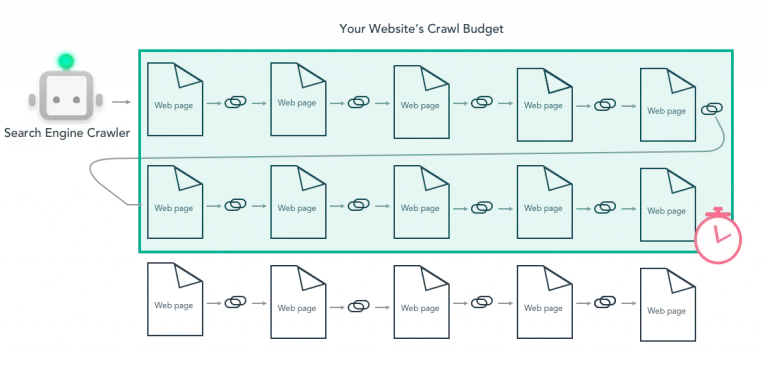
WHAT IS CRAWL BUDGET?
Crawl budget is the number of URLs crawled by a search engine during each session on your website. This number is determined based on a combination of factors – grouped around the size, health, and popularity of your website.
WEBSITE SIZE
Smaller, less complex websites likely don't need to worry about crawl budget as much as larger, more complex websites. The more pages on your site, the more likely it is that Google will miss important pages due to various factors.
If are the webmaster of an enterprise website — or a site with millions of pages — optimizing your crawl budget is vital.
WEBSITE HEALTH
The health of your URLs refers to how fast your pages load for search engines, whether there are any status code errors on those pages, as well as any limits you may have set on your pages through Google Search Console.
If you are a webmaster with dealing with any of these technical issues, you may simply need to invest resources into technical SEO so Google can discover more of your website during its visits.
WEBSITE POPULARITY
The popularity of your URLs refers to the amount of traffic, number of inbound links, and freshness on each of the URLs of your website.
If you are a webmaster with low traffic, few inbound links, and outdated content on your high-priority pages, this is the non-technical area of crawl budget optimization that you can quickly and easily invest in.
CRAWL RATE AND CRAWL DEMAND
Beyond the above definition, a site's crawl budget can also be defined by the crawl rate limit and crawl demand of a given domain. Taking crawl rate and crawl demand together, Google defines crawl budget as "the number of URLs Googlebot can and wants to crawl."
CRAWL RATE LIMIT
Google defines "crawl rate limit" as the maximum fetching rate for a given site and says that it is determined by:
1.) The maximum number of simultaneous parallel connections that Googlebot can use to crawl a site.
2.) The delay in time between fetches.
As mentioned above, the health of a site will play a role in the crawl rate limit for a particular domain. If the site is slow or has server errors, the crawl rate limit will decrease and a lower number of pages will be indexed per site crawl.
One way to maximize the use of your site's crawl rate limit utilize Google Search Console. You can set crawl rate limits in Search Console to signal parts of your site you don't want Googlebot to crawl, and increase the chances of the search engine crawling your most important pages.
CRAWL DEMAND
The other important factor in determining how often Google crawls a site, is related to the popularity of a site — as mentioned above. High-traffic sites tend to be crawled more frequently than sites that appear to be less relevant to search engine users.
Ultimately, the goal of Googlebot is to ensure that the index remains fresh. New, currently relevant content will be prioritized for crawling, while older, stale content will be deprioritized.
WHY DOES GOOGLE CARE ABOUT CRAWL BUDGET?
When you publish a page on your website, Google won’t necessarily index and rank it. In order for the page to appear in search results, the search engine has to crawl it first – and this can be problematic.
Google doesn’t have infinite time and resources to crawl every page of every website all the time. Over the last decade, as the internet has grown in size and complexity, they have acknowledged their limitations and disclosed that they discover only a fraction of the internet’s content.
That makes it the webmasters’ job to factor “crawl budget” into their technical SEO strategy, such that Google is able to discover and crawl the “right” URLs more often.
WHAT FACTORS HAVE AN IMPACT ON CRAWL BUDGET?
Here are just a few of the factors that have a negative impact on crawl budget:
- Slow page load time
- Duplicate content
- Low-quality content
- 404 error pages
- Faceted navigation
- Session identifiers
HOW CAN A WEBSITE BE OPTIMIZED FOR SEO CRAWL BUDGET?
Here are just a few of the ways a website can be optimized for Googlebot crawlers — crawl rate and crawl demand.
Do a Log file analysis
Doing a log file analysis for your site is a good place to start. A log file analysis can help webmasters determine how frequently Googlebot is visiting your site and if certain pages are being crawled more often than others.
Additionally, website owners can learn if there are certain areas or pages on a website that Googlebot is unaware of or if Googlebot is facing accessibility issues on certain areas of a website.
Improve page load times for Bots
Page speed is an important factor in determining the health of a given site. Fast page speed ultimately increases the number of pages Googlebot can crawl and the likelihood that pages on site will be crawled and indexed quickly.
One way to increase load times for bots — without needing to eliminate javascript or CSS that enhances user experience — is to utilize dynamic rendering software. Dynamic rendering allows you to offer one version of your website optimized for the Googlebot crawling experience and one version optimized for user experience.
With dynamic rendering, a static HTML version of a given web page is created to help Googlebot understand the content of the page without running into crawling issues associated with javascript and CSS code irrelevant to the information Googlebot needs to index the page.
Use canonical tags for original content
Use canonical tags in order to avoid issues with duplicate content and make sure Googlebot prioritizes indexing the original version of a piece of content.
Increase the number of external links to high-priority URLs
High domain authority sites and sites with a lot of backlinks are more likely to be crawled frequently because the site's content is seen as more authoritative and relevant across the web. The more URLs leading back to your website that Googlebot comes across as it is crawling other sites, the more it signals to Google that your web content is relevant to users.
Improve internal links across your website
Strong internal links can have a positive impact on Googlebot's crawling experience because it helps Google connect relevant URLs — making sure Googlebot can find important related content.
Redirect 404 error code pages
Googlebot cannot crawl pages with 404 errors. It's important that search engine crawlers are routed to the correct page.
TRY TO AVOID REDIRECT CHAINS
Although it is better to redirect 404 pages to pages without errors, it's also to try to limit redirect chains as much as possible. There are bound to be some redirects associated with your domain. But too many, chained together, will hurt your crawl limit and disincentivize search engine crawlers from reaching important pages on your site.
One or two redirects here and there might not damage you much, but it’s something that everybody needs to take good care of nevertheless.
Use robots.txt files to block parts of your site you don’t want crawled
A robots.txt file is used to tell web robots (like search engine crawlers) which pages to crawl on a given site and how to crawl them. A robots.txt file specifies which user agents are allowed to crawl specific pages by marking those with the instructions "disallow" or "allow."
Here's what the format looks like:
User-agent: [user-agent name]Disallow: [URL string not to be crawled]
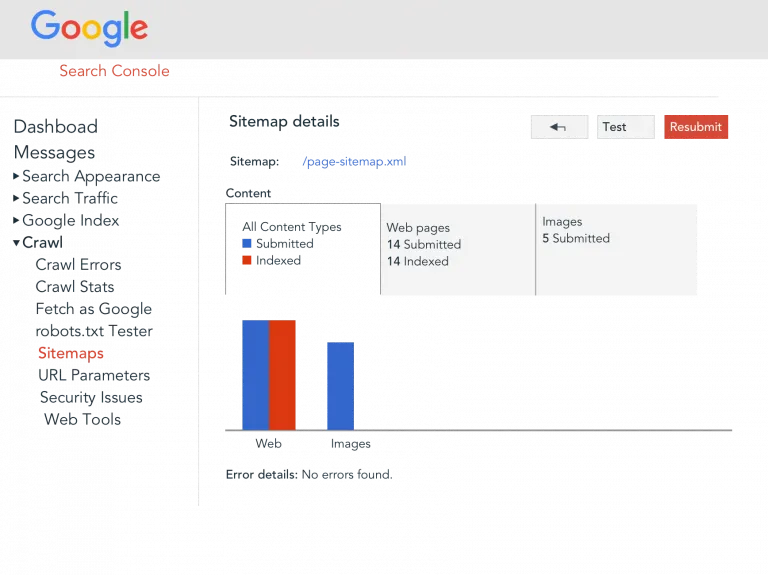
UPDATE YOUR XML SITEMAP
XML site maps exist to help webmasters improve SEO performance for their website, and submitting an XML sitemap after making content changes can help crawlers find and index pages on your site more easily.
Although Google doesn't require site maps — it's not an SEO ranking factor — using them can speed up the crawling process, thereby maximizing the crawl budget for your site and enabling Google to index your pages more quickly. In order to submit, or resubmit, an XML sitemap for your website, you can use Google Search Console and follow these steps:
Click on "Crawl" > "Sitemaps" > select "XML sitemap" > click the red "Resubmit" button)
WHAT ARE THE BENEFITS OF CRAWL BUDGET OPTIMIZATION?
In short, Google spends less time on low-quality and low-priority pages and more time on the most important, high-value parts of your site.
In a given visit to your website:
- Google is able to find more new and essential content faster
- Google is able to add more new and essential content to search results faster
The downstream benefits are increases across the board in ranking keywords, organic traffic, and organic channel revenue.
HOW CAN I IMPROVE MY CRAWL BUDGET?
If you are looking for a solution to optimize the crawl budget of your website, look no further than Huckabuy. Our software platform leverages Google’s latest technical initiatives, including dynamic rendering, page experience, and structured data to optimize the entire first half of the SEO funnel, so that search engines can crawl, render, and index more content from your website.
Search engines, like Google, use two factors – crawl rate limit and crawl demand – to determine the number of web pages they are able to crawl in a given session per domain. Some factors affecting crawl demand and crawl limit include site speed, available server resources, server errors, total external linking URLs, and site traffic. The number of pages a search engine bot is able to crawl in a given session for your website. Crawl budgets can be improved by implementing various technical SEO practices.
What resources exist to improve crawl budget?
If you are looking for a solution to optimize the crawl budget of your website, look no further than Huckabuy. Our software platform leverages Google's latest technical initiatives, including dynamic rendering, page experience, and structured data to optimize the entire first half of the SEO funnel, so that search engines can crawl, render, and index more content from your website.