Introduction to Canonicalization for Technical Seo
Search engines experience website content differently than humans. For search engines, every unique URL is a separate page. And if a single page on your website is accessible by multiple URLs with similar or near similar content, Google interprets them as duplicate versions of the same page. Consequently, Google will choose one URL as the original and most important piece of content and index that. Sometimes, they make a mistake and choose the wrong one. This makes it important to take the proactive step of telling Google which one is which.
What are canonical tags?
A canonical tag is a snippet of HMTL code that defines the main version from duplicate or similar pages. It looks like the following: link rel = "canonical" href = "example.com". "link rel" means this link is the master version of the page and "href = example.com" means the canonical version can be found at the specified url.
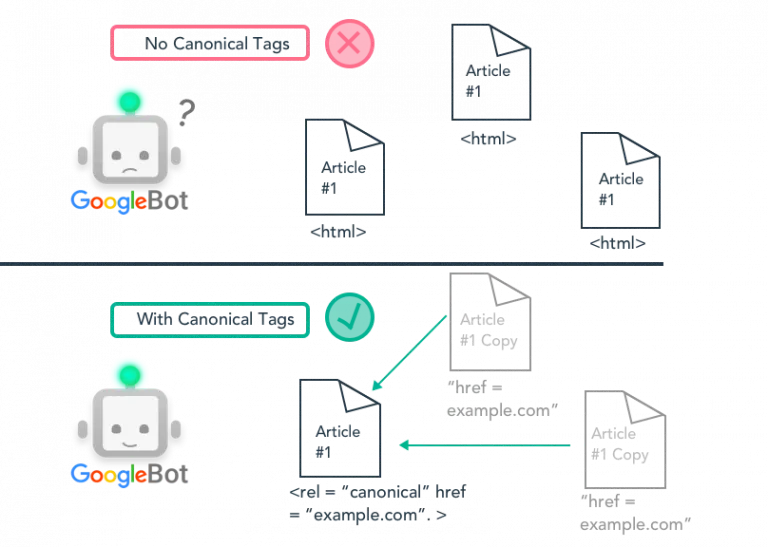
The canonical tag was introduced by the major search engines in 2009 as a way for webmasters to solve duplicate content issues and preserve link equity and rankings by specifying which version should be indexed to appear in search results. It's like the technical SEO form of an academic citation. In the same way you cite a source on a research paper to avoid plagiarism, you use a canonical tag to prevent duplicate content penalties among similar URLs.
Why is canonicalization good for SEO?
On a high level, canonicalization is good for SEO because it helps Google make sense of duplicate content and minimizes the risk that they pick the wrong URL as the canonical version. With canonical tags in place, Google can correctly consolidate link equity, index, and rank the main version of your content for relevant queries. It also helps preserve crawl budget so they have more time to spend discovering other important areas of your website.
What are the best practices for canonicalization?
Here is some advice to consider when starting out:
- Use the URL Inspection Tool in Google Search Console to see which page Google considers to be the canonical version.
- When deciding between using a redirect or canonical tag, go with the redirect unless the user experience would be diminished in some way.
- When choosing which page to use the canonical tag on, go with the version you think is the most important. A good proxy is the URL with the most links and traffic.
- The canonical tag should only be used for identical or near identical URLs. It is not to be used for topical grouping.